


II. Introduction▲
II-A. VFS en quelques mots▲
VFS, pour Virtual File System est une solution choisie pour représenter une hiérarchie de fichiers dans le kernel Linux.
Dans une philosophie Linux où tout est fichier, aussi bien configuration/état du système (/etc et /proc) que périphériques (/dev), il est nécessaire de fournir une couche d'abstraction afin que les différents modules communiquent au kernel leur représentation sous forme de fichiers. Le kernel, à son tour, communiquera aux diverses applications via une certaine API, qui correspond aux fonctions système comme open, close, read, write, mmap, ...
II-B. Structure globale de VFS▲
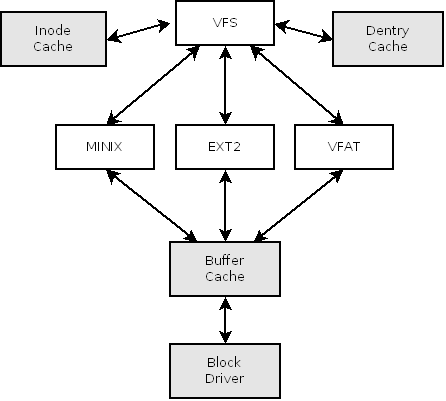
Ce schéma est un rapide résumé des interactions entre VFS et les modules de filesystem (MINIX, EXT2, VFAT, etc.)
Chaque filesystem obéit à différentes spécifications quant à la représentation des données sur le disque. L'emploi de VFS permet au kernel de ne pas avoir à tenir compte de leurs topologies.
VFS dispose d'une structure très proche du filesystem ext2, ce qui permet de minimaliser le code dédié à l'abstraction du filesystem, et de n'avoir que de simples copies de valeurs dans les structures appropriées. Dans la suite de ce document, je parlerai presque exclusivement des structures de VFS et non de celles spécifiques aux filesystem.
Lors de l'ajout d'un filesystem, ce qui se produit soit au démarrage de la machine, soit lorsque le kernel en éprouve la nécessité (si le driver est compilé sous forme modulaire, et le kernel configuré pour le charger dynamiquement) celui-ci s'enregistre auprès du kernel, en lui fournissant une structure, le Superblock, contenant des pointeurs de fonctions qui seront utilisés pour le parcours de l'arborescence, l'allocation et l'initialisation d'inodes, ainsi que de nombreuses autres opérations où il peut être nécessaire que le driver intervienne.
Retenez qu'une inode est une structure qui contient toutes sortes d'informations et métadonnées relatives à un fichier (l'exemple le plus éloquent est la date de modification), et qui de plus détient un numéro i_ino unique qui correspond au fichier. On notera aussi que le nom d'un fichier n'est pas stocké dans l'inode.
Par la suite, lorsqu'un programme demandera l'accès à une donnée dans l'arborescence de fichiers, ce seront ces fonctions, spécifiques au filesystem auquel appartient la donnée, qui seront appelées. Ainsi, si l'on étudie le comportement de la commande cat, on a tout d'abord la recherche du fichier dans l'arborescence de dossiers, puis l'ouverture du fichier, sa lecture, et enfin sa fermeture. Chacune de ces étapes nécessite l'intervention du driver de ce filesystem.
La recherche d'un nœud dans une arborescence depuis le disque est une opération qui s'avère très coûteuse en terme de performance. Pour ext2 ou minix, il est nécessaire de lire, au minimum, autant de blocks de données sur le disque qu'il existe de nœuds jusqu'au fichier. Si l'on tient compte des temps de latence du périphérique, et du fait que les différents blocks ne sont probablement pas agencés bien dans l'ordre sur ce dernier, les temps d'accès mémoire sont bien plus intéressants. C'est cette dernière proposition qui est à l'origine d'une importante optimisation : les caches d'Inodes et de Dentries.
On trouvera le code relatif à VFS dans /usr/src/linux-2.6.x.y/fs/.
II-C. Inode Cache▲
L'inode cache est un espace mémoire réservé au stockage des dernières inodes lues afin d'optimiser la lecture de ces dernières sur le périphérique de stockage.
Il s'agit d'une table de hachage unique et commune à tous les systèmes de fichiers où chaque entrée est un pointeur vers une liste d'inodes possédant toutes le même hash.
static struct hlist_head *inode_hashtable __read_mostly;
Le hache correspondant à chaque inode dépend de son numéro (i_ino) et de l'adresse du VFS Superblock du filesystem auquel il appartient (on peut donc différencier plusieurs points de montage entre eux, car ils possèdent chacun leur propre VFS Superblock)
static static unsigned long hash(struct super_block *sb, unsigned long hashval);
NB : on notera qu'une recherche dans cette liste provoque la libération « asynchrone » des inodes marquées comme 'I_FREEING | I_CLEAR | I_WILL_FREE'.
Quand le système nécessite d'accéder à une inode 'inode', il calcule son hash, puis la recherche dans la liste située dans inode_hashtable[hash(sb, inode->i_ino)] L'inode portant le même numéro et appartenant au même système. C'est ce qu'illustre l'extrait suivant :
559.
560.
561.
562.
563.
564.
565.
566.
567.
568.
569.
static struct inode *find_inode_fast(struct super_block *sb,
struct hlist_head *head, unsigned long ino)
{
//...
hlist_for_each_entry(inode, node, head, i_hash) { //On each inode from the inode list
if (inode->i_ino != ino) //Not the same i_ino
continue;
if (inode->i_sb != sb) //Not the same superblock
continue;
//...
return inode ? Inode : NULL; //Return inode found or NULL
}
Quand le (file)système a besoin de récupérer une inode (via iget_locked ou iget5_locked), VFS commence par rechercher dans la liste des inodes existantes via la table de hachage.
Si l'inode en question est introuvable, elle sera alors allouée, verrouillée puis initialisée, avant d'être renvoyée. Le système incrémentera alors i_count qui correspond au nombre d'utilisations simultanées de l'inode. (Une inode avec un i_count = 0 correspond à une inode qui devra être libérée par le système. La mémoire en question pourra alors être à nouveau allouée pour une autre inode).
Lorsque le système charge une inode depuis le périphérique de stockage pour la première fois, il initialise i_count à 1, ce qui signifie que cette inode n'est utilisée que dans un seul contexte, par exemple pour un éditeur de texte. Si à nouveau, l'inode est demandée dans un second contexte, par exemple suite à une commande cat, alors i_count est incrémenté. Par la suite, si l'éditeur est quitté, imaginons avant que la commande cat ne termine son exécution, alors l'inode verra son champ i_count repasser à la valeur 1, et l'inode sera conservée par le noyau et continuera à être utilisée par cat. Enfin, la commande cat terminée, i_count passera à 0 et sera libéré.
Afin de signaler que l'utilisation d'une inode est terminée, on utilisera iput ce qui diminuera i_count et si nécessaire appellera les fonctions nécessaires à la libération de l'inode.
On constate donc que lors de l'utilisation simultanée de la même inode dans plusieurs contextes, seul une unique instance subsiste en mémoire.
Les inodes qui ne sont plus utilisées (sans dentry lié, aucun dfile descriptor (descripteur de fichier) ouvert) sont placées dans la liste des inodes inutilisées et seront libérées par la suite via dispose_list().
II-D. Dentry Cache▲
On appelle Dentries(directory entries / entrées de répertoire) les structures qui contiennent l'association entre un nom de fichier et le numéro d'inode correspondant. Elles sont générées par la fonction lookup, implémentée dans chaque filesystem, qui prend en paramètre l'inode du répertoire parcouru (le premier est la racine "/") et le nom du fichier/répertoire. Elle doit remplir une structure dentry qui lui est passée en paramètre, soit par l'inode correspondante, soit par l'inode invalide : 'NULL' (qui est associée à l'inexistante de l'inode recherchée).
Un exemple flagrant, pour vous rendre compte des répercussions du dentry cache sur les performances est de simplement lister ('ls') un répertoire qui n'a pas été accédé depuis le montage du disque. Renouveler l'opération une seconde fois, la différence de temps est alors flagrante.
A noter que le DentryCache est un « maître » de l'InodeCache, c'est à dire que si une dentry existe dans le cache, alors l'inode associée existe nécessairement. De même, si une dentry est détruite, alors l'inode associée est aussi détruite.
10.
11.
12.
13.
14.
15.
/*
* Notes on the allocation strategy:
*
* The dcache is a master of the icache - whenever a dcache entry
* exists, the inode will always exist. "iput()" is done either when
* the dcache entry is deleted or garbage collected.
*/
Tout comme l'Inode Cache, on retrouve la table de hashage :
64.
65.
66.
67.
68.
69.
static inline struct hlist_head *d_hash(struct dentry *parent,
unsigned long hash)
{
hash += ((unsigned long) parent ^ GOLDEN_RATIO_PRIME) / L1_CACHE_BYTES;
hash = hash ^ ((hash ^ GOLDEN_RATIO_PRIME) >> D_HASHBITS);
return dentry_hashtable + (hash & D_HASHMASK);
}
La fonction de hashage des Dentries diffère de celle des inodes. On assiste à un pré-hashage à partir du nom complet de la dentry, puis la valeur résultat est re-hashée avec l'adresse de la dentry parente de celle-ci.
static struct hlist_head *dentry_hashtable __read_mostly;
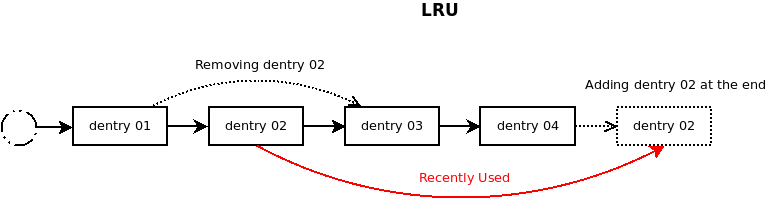
Afin d'améliorer les performances, le système maintient une list des Last Recently Used (LRU : Derniers Récemment Utilisés) dentries contenues dans le cache. Le système dispose de deux LRU Lists. Plus une dentry est utilisée, plus elle sera située vers la fin. Lors de la création d'une dentry, elle est ajoutée à la fin de la première LRU List. Dans le cas où le cache est plein, c'est le premier maillon de la liste qui sera réutilisé pour être placé en fin de liste. Si la dentry est à nouveau utilisée, alors elle sera migrée dans la liste de second niveau, où à chaque utilisation la dentry sera repositionnée en fin de liste. On peut ainsi aisément trouver les dentries les moins utilisées (positionnées en début de liste) afin de les libérer si nécessaire.
II-E. Monter un filesystem▲
Monter un filesystem est un évènement qui peut sembler banal dans la vie de tous les jours d'un utilisateur de Linux. La commande est de ce type :
$ mount -t iso9660 -o ro /dev/sr0 /mnt/cdromIci, mount ne fait que passer la main au kernel avec les arguments suivants :
- Le type de filesystem (iso9660)
- Le périphérique (/dev/sr0)
- Le point de montage /mnt/cdrom
- Une chaine de caractères destinée à être interprétée par le filesystem (ici aucune)
- Divers flags (ici ro)
Ceci se fait via la fonction do_mount(). Cette dernière commence par récupérer les flags de montage, vérifie l'existence du point de montage puis passe la main à do_new_mount dans l'exemple ci-dessus.
C'est alors que do_new_mount() tente d'interpréter la chaine fstype et de récupérer la structure décrivant le filesystem correspondant. Dans le cas d'une compilation sous forme de module, ce dernier pourra être chargé par le système quand il devient nécessaire(1).
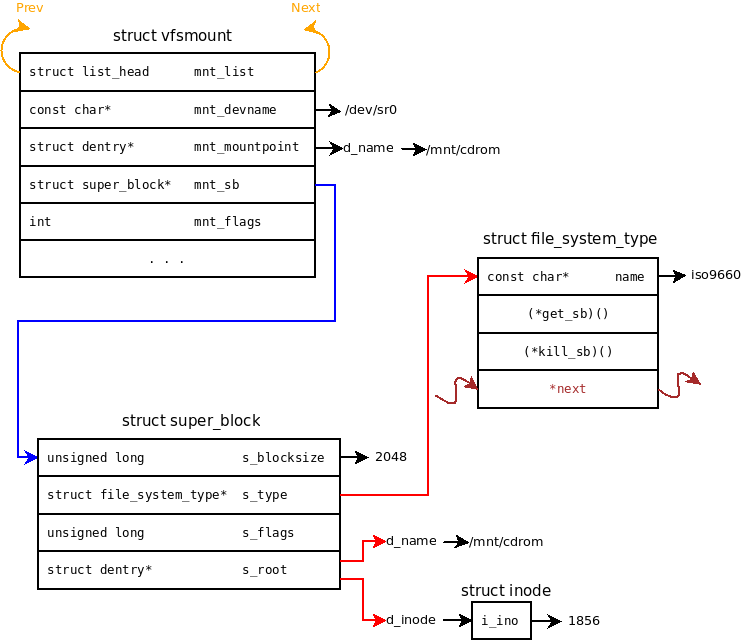
Vient alors le tour de vfs_kern_mount() qui va créer la structure vfsmount où seront stockées les informations relatives au montage. C'est alors que la fonction get_sb du filesystem est appelée. A ce stade, rien ne garantit que la chaine passée en paramètre corresponde à un périphérique valide(2).
Si cette dernière opération est une réussite, alors le noyau tentera de placer le filesystem au point de montage associé. En cas d'échec, le superblock alloué (et la structure vfsmount) est libéré.
1906.
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
913.
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
998.
struct vfsmount *
do_kern_mount(const char *fstype, int flags, const char *name, void *data)
Dans le cas où la commande précédente serait un succès, nous aurions quelque chose de similaire à la figure suivante :
(1)La liste des systèmes de fichiers actuellement chargée dans le kernel est disponible via la commande : « cat /proc/filesystems ».
(2)Bien sûr, le binaire mount peut très bien effectuer lui même toutes sortes de vérifications. Nous ne nous intéressons ici qu'à l'aspect kernel.
II-F. Démonter un filesystem▲
Une fois les tâches de l'utilisateur accomplies, que ce soit lors de l'arrêt du système ou bien simplement car l'utilisateur souhaite par exemple déconnecter un périphérique de stockage amovible, ou encore un administrateur effectuer une maintenance, il est alors nécessaire de démonter le filesystem.
$ umount /mnt/cdromLe démontage (unmounting) d'un filesystem est bien sur l'action réciproque du montage. Un système de fichiers ne peut être démonté tant qu'il est utilisé par une application. Il est donc nécessaire que toutes les inodes détenues par le filesystem puissent être libérées. Suite à une commande umount, le noyau recherche dans le cache des inodes toutes les inodes appartenant au système de fichiers qui doit être démonté. Elles sont alors libérées (si nécessaire, les modifications sont écrites sur le disque). Le noyau récupère alors le superblock, et là encore, si nécessaire, écrit les modifications sur le disque. La mémoire est alors libérée, la structure vfsmount elle aussi supprimée de la mnt_list et libérée.